< September 2002 >
30th: Just a short note. Well If you're reading this then you have been succesfully redirected to my new host! I've not posted the last couple of days while waiting for the DNS to fully propogate, In the meantime what have I been upto? Well getting back to university for a start, yes after another summer excursion into the realms of full-time employment I venture back into the rarefied aptmosphere of academic life. On th web front you may want to check out the new pheonix release from the Mozilla organisation, its not as fully featured as the real Mozilla releases but it is definately worth checking out as a lightweight browser, bear in mind though that it is only version 0.1 so problems are to be expected.
In the meantime I've been getting back into reading mode an I am currently working through a book, written by Garret Mattingly, about The Defeat of Spanish Armada, as I took geography as my "humanities" subject at school my historical knowledge of this subject is a little brief so I thought it best to educate myself concerning it. In the course og my reading I have encountered a new word, magniloquent. This caused me to reflect on how my learning of general vocabulary had seemed to diminish to a large extent, reading books from other disciplines has been a refreshing course of action for me.
24th: The HTML profile attribute. Mark Pilgrim gave a pointer today to an interesting article regarding which makes mention of the profile attribute, which is relevant to my earlier post about RSS autodiscovery, I had a brief email exchange with Mark about profiles a few days ago and I am glad to see he has found an interesting resource that I can learn from. The article, "HyperRDF", is about producing RDF schemas from XHTML. It is interesting reading if you are interested in learning more about the semantic web.
What is an accessible website? well Jim Byrne has a few ideas in his new article which discusses how accessibility can be interpreted in different ways. In other news I'm glad to say that one of my favourite blogs, glish.com, has had a few new posts after a break for several weeks, check it out.
23rd: CSS stylesheet for RSS. I've been working on a style sheet for simple styling of RSS feeds. I'll get around to including it in my CSS templates zip file soon, however for the time being here is a link to the the CSS in all it's glory. I'll admit to it being quite basic at the moment, but at least it is a little easier on the eye than a block of text with no formatting. To call the CSS file you can use the XML stylesheet instruction<?xml-stylesheet href="style.css" type="text/css"?>
The site has been experienceing server problems recently but I am planning a move to another host in the near future. Because of this some of my plans for the site have been put on hold until I have moved hosts and have the oportunity to develop my site on the new setup. Look forward to more RSS feeds in addition to the articles feed I already have.
If your interested in learning more about RSS I can recommend rss.benhammersley.com and www.diveintomark.org for starters.
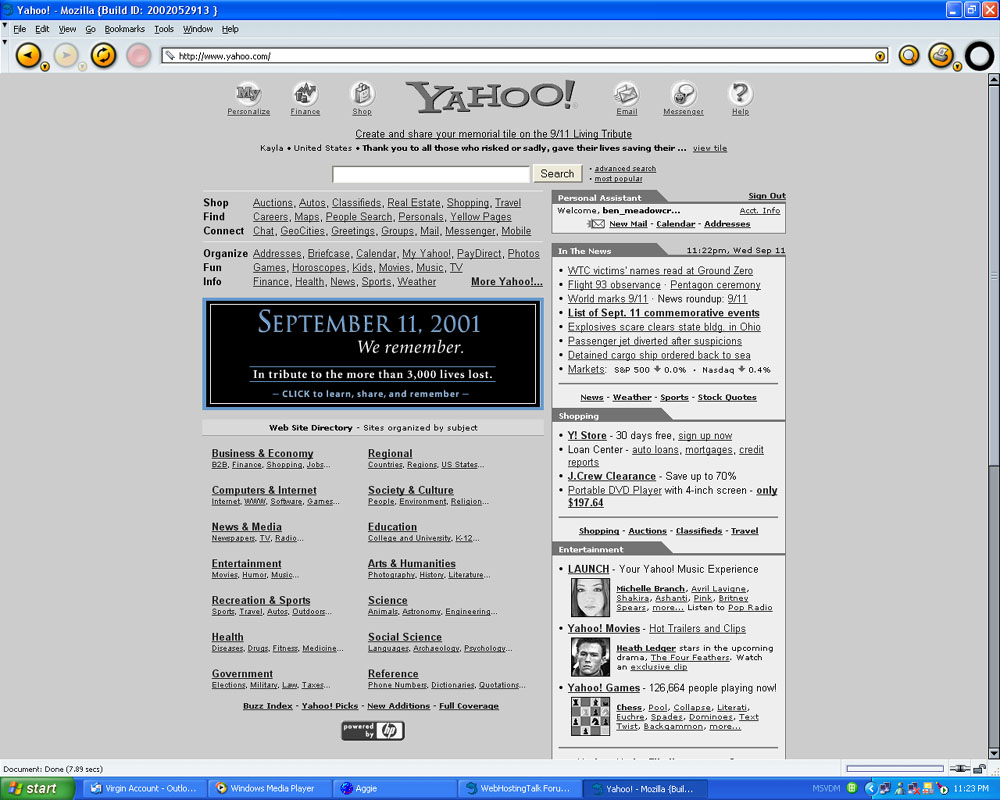
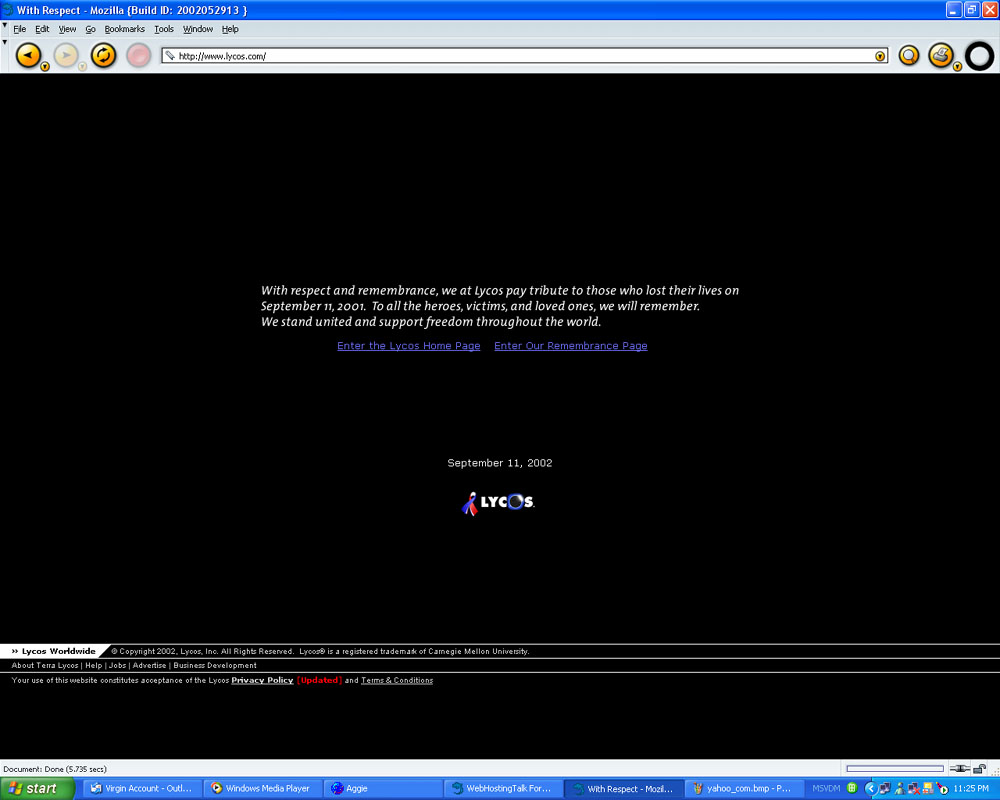
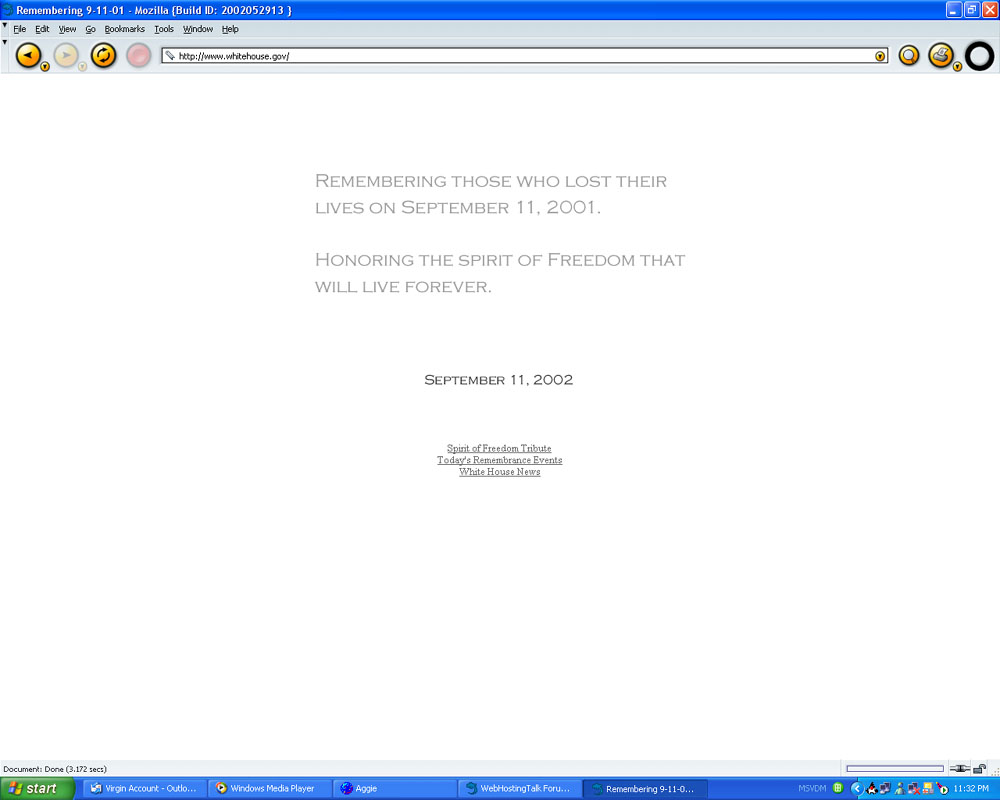
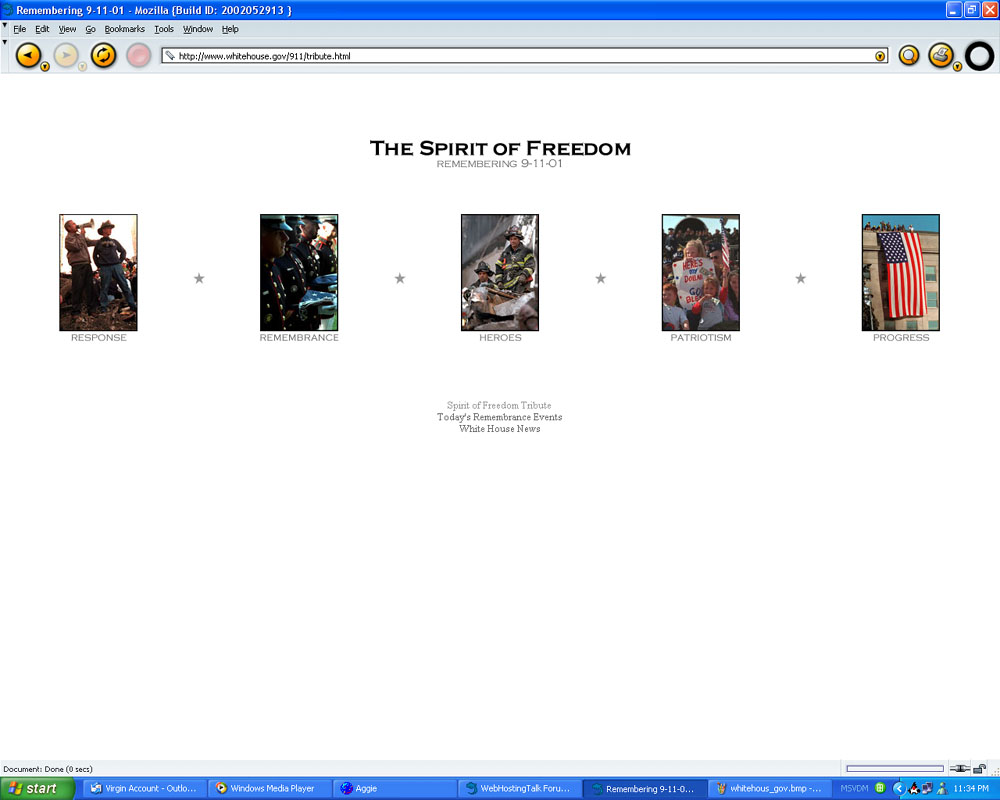
18th: How sites remembered. Presented are screenshots of how a few websites remembered what happened one year and one week ago.
- Yahoo.com [183Kb],
- Lycos.com [96Kb],
- Amazon.com [331Kb],
- WhiteHouse.gov (1) [76Kb],
- Whitehouse.gov (2) [97Kb].
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
12th: RSS Autodiscovery. can current practice on auto discovery be improved?
Why do I care? Well, the current practice is a misuse of the rel attribute and is not taking advantage of the methods defined in the HTML 4 specs (and thus in XHTML 1 etc).
Example of the current practice<link rel="alternate" type="application/rss+xml" title="RSS" href="http://www.aurl.example/rss.xml">
Why is it a misuse of the rel attribute? See http://www.w3.org/TR/html401/types.html#type-links
- Alternate
- Designates substitute versions for the document in which the link occurs. When used together with the lang attribute, it implies a translated version of the document. When used together with the media attribute, it implies a version designed for a different medium (or media).
Merely having rel="alternate" is insufficient, it is an alternate what? Determining this by (unregistered) mime types is (IMO) a mistake, limits the use of alternate for truly alternate meta data choices and is undefined by the HTML specs.
To extend the keywords available to use in the rel attribute requires the document author to specify a profile to specify these new keywords. See http://www.w3.org/TR/html401/struct/global.html#h-7.4.4 and http://www.w3.org/TR/html401/struct/global.html#profiles
In general, specifying meta data involves two steps:
- Declaring a property and a value for that property. This may be done in two ways:
- From within a document, via the META element.
- From outside a document, by linking to meta data via the LINK element (see the section on link types).
- Referring to a profile where the property and its legal values are defined. To designate a profile, use the profile attribute of the HEAD element.
These points specify how to reference Meta data, and the like, from within a HTML document. The current practice does not reflect HTML's recommendations on this and should be modified to be in conformance. My proposal is the following.
The head element of the page should contain a profile element
e.g. <head profile="http://www.someurl.org/RSSMetaDataProfile/">
The link element pointing to the RSS feed should have a rel attribute, the attribute value is defined by the profile, the profile can be a single URL identifying the profile used it's format is not specified by HTML (it could just point to an English language specification, for example the RSS 1.0 spec, which states the valid values.)
For example
<link rel="RSS" type="application/xml" title="RSS weblog" href="http://www.aurl.example/rss_weblog_channel.xml" >
<link rel="alternate RSS" type="application/xml" title="RSS articles" href="http://www.aurl.example/rss_articles_channel.xml" >
Now that the alternate value is not artificially overloaded it is possible to use it to correctly specify an alternate choice between two specified link types, rather than an indeterminate alternate choice.
6th: When Photoshop Goes Bad.
 &
& 
5th: Recommended RSS reading. After beginning to implement some RSS feeds on my site it feels like I've stumbled into a fragmented scene of competing versions. The scene is much different to working with W3 standards which are generally only published after periods of consultation etc, the development of RSS seems to be going on between competing groups of people with development decisions published on weblogs and implemented almost immediately by the relevant group, Although this is an effective method of driving traffic to certain sites I'm not convinced as to it's merit for drafting standards which can be implemented uniformly. Without a centralised repository for the specification (or at least one that keeps up with these changes) it is difficult for someone to jump on board immediately and make full use of the exciting possibilities of RSS.
Having said that it's not all bad news, if you are happy to keep it simple writing RSS that is interoperable between various news aggregators seems to be quite possible. An interesting article I've recently come across is the RSS Tutorial for Content Publishers and Webmasters, this does a good job of explaining the differences between the two main versions of RSS, 0.9x and 1.0. Another weblog, Dive into Mark, is where I read an interesting article on RSS 2.0.
Well with all this talk of RSS feeds etc I though it might be a good idea to link to the site that demonstrates some of the potential RSS offers, holovaty.com allows readers to submit queries that return a RSS feed of content that matches the keywords submitted. A nicely designed site with interesting material to boot!